

硅谷爆出核弹级新闻:
20亿美金(约 ¥143 亿)
史上最贵种子轮诞生!

你敢相信吗,一家公司刚成立,还没发布任何产品,就以20亿美元刷新「史上最大种子轮」圈钱纪录。
这家公司,就是TML(Thinking Machines Lab),由 OpenAI前任 CTO Mira Murati 创办。

这个项目的领投方是硅谷金主爸爸a16z。
跟投名单闪瞎眼:英伟达、AMD、思科、Accel、ServiceNow、Jane Street ……,一众大佬赫然在列。

1、企业定制型AI:用强化学习把模型和客户KPI(营收、利润等)强绑定,俗称 “RL for Business”,说白了,我要给你定制能帮你企业赚钱的AI。
2、面向大众的消费级产品:外界猜是下一代ChatGPT竞品,仍在保密中。
这两项,随便哪一个,拿出来都很诱人。
而且,特别值得注意的是,投资人强调,他们更看重的【企业定制型AI】。
Why?道理很简单↓
一、钱在哪,就去哪
资本不想再听模型多聪明,他们要“帮我多赚钱”的硬指标,只认收益。
消费级AI是烧钱赚吆喝,企业级市场才是真金矿,才是真正能够为AI买单的群体。
二、不跟巨头硬刚,修建自己护城河
通用大模型市场基本被GPT、Claude、Gemini、Grok占好坑了。
TML如果去卷模型,很难突围,但行业定制需要深耦合数据+专业流程,进入门槛高、切换成本大,能形成持久黏性和数据壁垒。
三、合规红线友好,容易落地
金融、医疗、政企客户常说“数据出不去,模型必须进来”。这事儿,国外也一样,甚至更严苛(想想GDPR)!
TML提供本地或私有云定制模型,既绕开合规红线,也减少数据迁移/泄漏风险,是企业级AI采购时的硬指标。
四、开源打底,让企业用户省钱又省力
讲真,这一点必须要感谢我们的DeepSeek,彻底让开源模型占了上风,Llama做了这么久没有做好的市场教育,被DeepSeek半年教育透了。
所以,TML不走OpenAI砸钱训巨模的老路,反而以开源模型为起点,再用「模型层融合」技术,就像拼乐高一样,快速组装出企业专属AI。
便宜、灵活、上线快,用户接受度高。
五、客户黏性更强
通过RL for Business(业务强化学习),能直接绑定用户核心业务:业务、收入、增长。
RL‑based模型能24×7持续在线学习,而不是一次性精调后就冻结,业务一变,模型秒跟进。这种闭环更新只有定制方案才能做到。
当然,客户锁定性也更强,只要你上了我的“贼船”,就下不来了
英伟达、AMD、思科的内心戏
巨头们不是人傻钱多,他们在押注一个未来:企业AI定制,即将井喷!
英伟达和AMD既是投资人,更是卖“铲子”(GPU)的。同样,思科是老牌的基础架构厂商,也是卖铲子柄的。
企业级AI定制对算力铲子需求巨大,基础设施改造也能拉动一波,而且还都是资源独占,不能复用。
这招叫:我投资你,是为了让你多买我的货!
堪称硅谷最强“带货闭环”了。

看到硅谷这波,我们是不是也该期待点什么了。
这些年一直混toB圈,深知生成式AI对toB市场影响有限,但是Agentic AI、智能体可不一样,一定会带来大模型在企业级市场的规模化落地。
为什么这么说?前面巨头们的动作已经说明问题,再看看两者的小比较,是不是就更有谱了↓
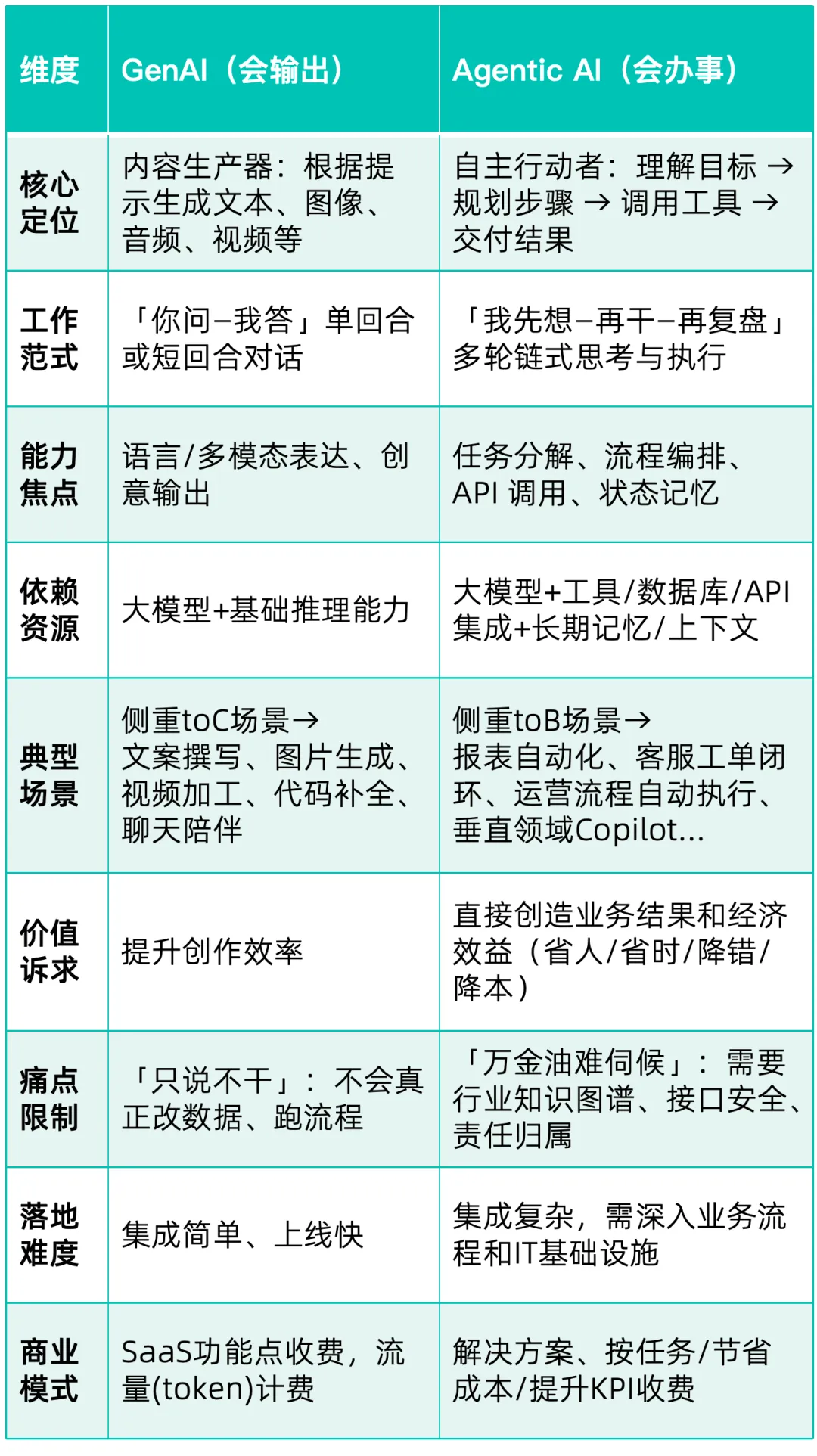
这么说吧,企业AI规模化落地,拐点已到,还没有所动作的,要抓紧加码了。
20亿美元种子轮,不是故事的结局,而是开始!

相关文章



![喜大普奔!黑森林开源发布FLUX.1 Kontext [dev] 图像编辑模型,6大超实用场景](https://www.runman.ai/wp-content/uploads/2025/06/1750988462-1.png)



